The image below is a simplified and easy-to-understand illustration of how hashing and salting work. The main takeaway from this post- multiple users can have the same password, but will all have different salt values, thus making their hash result value different, and when you authenticate, you authenticate by the hash result value of your passwords, which is virtually always going to be unique for each user record:
Simple, no?
Even in the case of 2 users having the same hash result, the usernames will/should not be the same, so you still have distinct accounts, because UserID is also checked in the authentication process.
Companies increasingly (and for good data privacy reasons) do not even store the clear text textbox value you enter when you sign up for and then log into Fb, Google, Amazon, etc- they check your entered password's hash result against the hash result they have for your user/account record either from when you registered or last changed your password.
You should know at least the surface topics surrounding TQM (Total Quality Management) because nearly all modern businesses practice TQM strategies and tactics to reduce costs and ensure top quality.
But first, check out this old video clip of America discovering something that ironically, an American (W. Edwards Deming) exported to Japan with great success years before:
1980 NBC News Report: "If Japan Can, Why Can't We?"
So big-Q "Quality" became a bit hit and has been embedded in process management throughout the globe ever since.
I think he has a point here.
Here are some Quality buzz words that surely you've heard before:
ASQ - American Society for Quality "Black Belt" - Ooo. Ahh. It does mean something. It means a person has passed a series of very difficult exams on statistics and statistical process control for quality based on the quantitative technics and measures originated in Japan by W. Edwards Deming.
ISO 9001 - the International standard of a Quality Management System that is used to certify that business processes follow standard process and product guidelines. Kaizen - a long-term approach to work that systematically seeks to achieve small, incremental changes in processes in order to improve efficiency and quality. Kanban - a visual system for managing work as it moves through a process.
Lean - a synonym for continuous improvement through balanced efficiency gains.
Example of statistical process control using UCL and LCL boundaries and a process (Fall Rate) improving.
LCL* - Lower Control Limit - The negative value beyond which a process is statistically unstable.
MAIC - Measure, Analyze, Improve, Control.
Service Level Agreements (SLA) - A contract between a service provider and end user that defines the expected level of service to the end user.
UCL* - Upper Control Limit - The positive value beyond which a process is statistically unstable.
Uptime - Uptime is a measure of the time a service is working and available and opposite of Downtime.
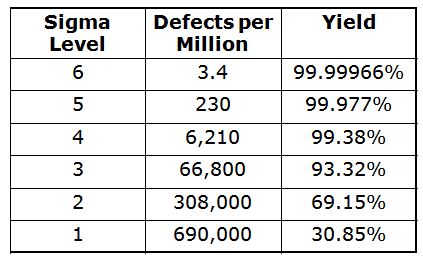
Six Sigma - a statistical approach to process improvement and quality control; sometimes defined as +/-3 three deviations for the mean ("6"), sometimes as +/-6 deviations from mean.
The table above gives you an idea of realistic process improvement numbers (66,800 == a lot of defective items)
History and W. Edwards Deming
Quality Management is a permanent organizational approach to continuous process improvement. It was successfully applied by W. Edwards Deming in post-WWII Japan. Deming's work began in August 1950 at the Hakone Convention Center in Tokyo, when Deming delivered a speech on what he called "Statistical Product Quality Administration".
He is credited with helping hasten Japanese recovery after the war and then later helping American companies embrace TQM and realize significant efficiency and quality gains.
Deming's 14 Points for Total Quality Management
*Measures such as standard deviation and other distribution-based statistics determine the LCL and UCL for a process (any process- temperature of a factory floor, time to assemble a component, download/upload speed, defects per million, etc.). References:
If you are serious about developing software, read this book. It contains timeless concepts you should know well.
I. Creational Patterns
1. Abstract Factory - facilitates the creation of similar objects that share interface
2. Builder- dynamic SQL statements and other dynamically constructed code
3.Factory Method- custom way to construct an object (vs. normal/default class constructor)
4. Prototype - create new instances by copying existing instances
5. Singleton - assurance of 1 and only 1 instance of an entity in an application
II.Structural Patterns
1. Adapter - a means of making an object compatible with another object via a common interface
2. Bridge - the decoupling of the adaptor/interface and the incompatible items (light switch w/fans)
3. Composite - a group of objects treated the same way as a single instance of the same type of object
4. Decorator - adding new functionality to a class via subclass with new methods, props, etc.
5. Façade - simplified interface to a complicated backend
6. Flyweight - reuse of an object instance to create more instances of the same type
7. Proxy - entity serving as a stand-in for the real thing. Often a wrapper for a more complex class.
III.Behavioral Patterns
1. Chain of Responsibility - source command is served by multiple processes with distinct linear roles.
2. Command - encapsulate a request as an object, works great with HttpRequest and user actions
3. Interpreter - dynamic culture and localization settings to display appropriate UI text
4. Iterator - centralize communication among objects that have a common interface (ie. TV remote)
5. Mediator - centralize complex communication and control among related objects
6. Memento - persist and recall object state
7. Observer - a central watcher picks up picks up broadcast messages from everywhere it observes (Twitter)
8. State - persists object state and can react in different ways according to attributes of its current state
9. Strategy - enabling an object to change/choose algorithm(s) at runtime
10. Template Method - great for interfaces; design skeleton w/base needs; allow concretes to implement details
11. Visitor - code execution varies according to visiting object (ie. keyboard keys, mice clicks, WiFi Routers, etc.)
For example, the typical route of encryption is data being encrypted when a value is stored to disk or sent over a network, then that data is decrypted by an authorized shared key holder application or service, and once the decrypted data has been used, it is invalidated or (if modified) encrypted and stored back on disk or over and across networks to eventually be stored on disk, in user privacy-respecting, encrypted format.
Encryption in Transit
You want to encrypt input, let's say a credit card number, from someone's cell phone. You need the credit card number to be encrypted while en route but ultimately decrypted after the transit is complete and the encrypted card data arrives at the merchant server. Here is what encryption in transit looks like:
Data securely encrypted on the wire going to and fro...
Encryption at Rest
Take for example the case of storing that same credit card data on the merchant's server so that the credit card information can be reused for future purchase payments. In this case, you will want to keep the data encrypted when you write it to disk in order to preserve user privacy.
The data is only decrypted when it is necessary (ie. when a new payment is processed, the encrypted data will be briefly decrypted so that it can be sent to the payment processor service).
Data safely encrypted on disk storage
Encrypted data is only ever decrypted on demand- when something requests it. Encrypted data is secure so long as only intended parties have the shared secret(s) key(s) to decrypt the messages.
OLAP can adequately be described as the storage of redundant copies of transactional records from OLTP and other database sources. This redundancy facilitates quick lookups for complex data analysis because data can be found via more and quicker (SQL execution) paths than normalized OLTP. And OLTP after all- should stick to its namesake and what it does best: processing, auditing, and backing up online transactions, no? Leave data analysis to separate OLAP Warehouses.
OLAP data is typically stored in large blocks of redundant data (the data is organized in ways to optimize and accelerate your data mining computations). Measures are derived from the records in the fact table and dimensions are derived from the dimension tables.
Facts are "measurements, metrics or facts of a particular process" -Wikipedia. Facts are the measurement of the record value: "$34.42 for today's closing stock price", "5,976 oranges sold at the market", "package delivered at 4.57pm", etc.
Dimensionsare "lists of related names–known as Members–all of which belong to a similar category in the user’s perception of a data". For example, months and quarters; cities, regions, countries, product line, domain business process metrics, etc.
Dimensions give you a set of things that you can measure and visualize in order to get a better pulse and better overall understanding of the current, past and even potential future (via regression models) shape of your data- which can often alert you to things you might not be able to see (certainly not as quickly or easily) in an OLTP-based Data Analysis model which is often tied to production tables out of necessity or "we don't have time or money to implement a Data Warehouse".
Yes, you definitely do need OLAP/DW capabilities if you think long-term about it. Having intimate knowledge of your operations and how you can change variables to better run your business? Why would any business person (excepting those committing fraud) not want that?
I'd say that implementing a true and effective OLAP environment is worth any project investment and would pay itself over and again in the way of better and more specific/actionable metrics that help administrators of operations make the best, data-backed decisions- some very critical decisions involving millions of dollars and sometimes lives. I'd like a better look at the data before making a multi-million dollar or life/death decision.
SAS, Hadoop, SSAS, with healthy doses of R and/or Python customization?- whatever data solution you choose, my advice is to go with something that has a great track record of providing the kind of solutions that your business and/or your industry require. Use the tool that your ETL developers can utilize effectively and that helps you to best meet the needs of your constituents with whom you will exchange data with (the company, the customer, industry and/or regional regulation compliance).
"The purpose of the OSI reference model is to guide vendors and developers so the digital communication products and software programs they create will interoperate, and to facilitate clear comparisons among communications tools." -Vikram Kumar
Abstract OSI Model
OSI Model cross-references with the protocols that facilitate network communication
The OSI model is a visualized and defined "meaning" of abstract data communication across networks. Some people have argued that the OSI model doesn't meet the needs to explain the abstract ideas in modern TCP:
"To make matters worse, the Internet's evolution, based on TCP/IP, never strictly followed the old OSI model at all. A reasonable person might ask whether people who talk about 'Layer 1' or 'Layer 3' aren’t blowing kisses at an old friend instead of recognizing the relevance of the original OSI model."
Ouch. Well, like it or not the OSI model (10 years on after this 2008 article was published) is still one of the best ways we as IT people have to describe network packet travel from wire to UI screen and back.
Any analogy or model works so long as we understand what happens when we send web requests out to networks (by clicking, by pressing enter, by having certain background services sending random telemetry, polling and other non-user issued web requests).
But standardization is important for globally agreed-upon understandings that serve as a common template and enable "apples to apples" communication on ideas being researched and the building of solutions worldwide, which, at this juncture in the 21st Century, is increasingly common.
It truly is a small world after all and I'd argue we really do neeeed to have standards like:
ISO 35.100 - Open Systems Interconnection
ISO 9001 Quality Management
ISO/IEC 27001 Information Security Management,
ISO 14001 Environmental Management
ISO 31000 - Risk management
...in order to communicate in a common language across the earth and prevent a sprawl of "20 ways to describe the same idea". Let's try to keep these things simple, standardized, and open to easy integrative communication.
This cannot be said enough. I have heard countless horror stories (and lived 1) of instances where backups were completing "successfully" but no one ever tested the restoration of those backups (which were, in fact, corrupt and not restore-able)- until it was too late. :/
Put in the time up front to make sure your data recovery strategy and high-availability guarantee actually "recover" and make "available" your data- the lifeblood of your organization.
It is important to remember that you can have a Secondary database server that is 100% in sync with the Primary database server, but if your application is not configured to make the switch (or your service host does not make the switch for you)- you will only have 1/2 of things recovered: the data, but not the data availability through the application.
Nearly every business wants to centralize their business data so that they can get an at-a-glance overview of what is going on at any given point in the day. Suppose, for instance, a company has its business data on 5 separate database servers, in various databases therein, across several different tables. And much of the data will need to be slightly modified (transformed) in order to make data types consistent and optimize it for quick and meaningful data analysis.
Assume the database servers are:
CMS, Orders (Dynamics 365 data)
Accounting (Sage 50 data)
Warehouse, Logistics (SAP data)
Field Service, Product Support (SalesForce data)
Call Center (TantaComm data)
Furthermore, the business wants to apply some custom logic to various fields so that certain calculations don't have to be made by the OLAP end users and applications.
ETL is just moving data from a Source to a Destination, often making some changes (transformations) along the way
Well, it all seems so complicated, right? How can all that disparate data be combined and standardized? It's not as complicated as allowing an ERP solution define how your various departments do their job. Some ERP products truly do have the functionality to satisfy 80-85% of the company business requirements. And when that is the case, by all means, companies should go that route.
But for instances where ERP of every business function is not working, you can use products like SSIS, Informatica, and Oracle Data Integrator to easily map ETL data visually and apply code operations to the data using a variety of programming languages.
But of course, there is no "one-size-fits-all 100% of our business needs" ERP solution; different business productivity software work better or worse for different industries, different departmental needs, for all manner of different reasons. Why care about the choice of business tool that your business' management and best minds know and have proven is most effective for their- often very specific- job?
Allowing a business to integrate the "best apps for each particular type of job" is nothing more than a sort of microservices architecture. But if we are working with custom code in these various LOB applications (at least some of the LOB apps will need custom API integrations so that they can talk to each other), with each new block of custom code, comes more decentralized code bases and decentralized test scripts...
All considered, I would argue that trying to put square pegs into round holes a la "ERP-everything" is a much, much, MUCH bigger effort than a well-developed and tested scheduled ETL Data Warehouse refresh process to centralize your company's data.
It's always a balance with software. Use the most effective apps for your organization and departmental requirements, but try to avoid the dependency hell that can come along with a poorly managed distributed application environment.
Here are the ETL steps in order, from the resource link below:
Extract the data from the external data sources such as line-of-business systems, CRM systems, relational databases, web services, and anywhere you have business data you want to summarize.
Transform the data. This includes cleansing the data and converting it to an OLAP-friendly data model. The OLAP-friendly data model traditionally consists of dimension and fact tables in a star or snowflake schema.
Load the data so that it can be quickly accessed by querying tools such as reports, dashboards, etc.
"90% of the requirements now is better than 100% of the requirements never" -Unknown
"These principles, when combined together, make it easy for a programmer to develop software that are easy to maintain and extend." -Robert 'Uncle Bob' Martin
S - Single-Responsibility - objects should only serve one purpose O - Open-Closed - types should be open to extending capabilities, closed to base changes L - Liskov Substitution - subtypes of base types should produce objects compatible with base I - Interface Segregation - client types do not have to depend on unused interface methods D - Dependency Inversion - rely on abstract templates, not prescriptive/restrictive concretes
Most developers know what a full database backup is. Did you know a differential backup is just a subset of the full backup? But what is the point of transaction log shipping in SQL Server?
A "transaction log" is just a subset of a subset of a full backup containing a set of all T-SQL transactions for a given (usually short span) amount of time; they are typically set at intervals of every few minutes but this varies according to application and data compliance needs.
A commenter in the referenced web link below aptly notes:
"the point of log shipping is to keep the secondary server closer to 100% synced than the full backups (which are much larger and produced much less frequently than log backups)." Log shipping can be used to serve as a constant "warm backup" (similar to SQL Server database mirroring) of all production transactions for a standby/failover SQL Server* as well as a dedicated Backup SQL Server as depicted here:
Setup if you have a fully-functioning Secondary Production SQL Server
Or, more commonly, the shipped backup logs are sent to a single Backup Server:
Typical production database server scenario, though the steps are a bit out of sequential order, if not (or due to) visual order
In short, a full backup contains the entire database you to recover- up to a certain point in time.
A differential backup is a subset of a backup (generally "full" backups contain days worth of data for bigger organizations)- it would only be prudent to include one or even four differential backups to ensure quick disaster recovery (and full recovery of vital customer data). Backup logs are chunks of SQL transactions that eventually compose the differential backup(s) and finally the entire full .bak file.
These 3 disaster recovery tools that SQL Server affords DBAs and developers allow you to restore your production data back to the point in time when your server failed:
Apply themost recent full backupof the prod server that went down*
Apply any differential backupssince the most recent full backup
Apply all transaction logs up to the point in time of the failure**
Apply all StandBy server transactions logs that may have occurred (if not ReadIOnly)
With all of this said, do be aware that different scenarios and requirements call for different kind of disaster recovery solutions. Consult with the experts and never neglect to TEST YOUR RESTORE PROCEDURE WITH ACTUAL .bak and .trn files- and then test the applications and services connected to those database servers against their restored/Secondary version to ensure you suffer as little downtime as possible in the event of a database emergency.
What a restoration timeline might look like
*Note(!) to the questions on Microsoft Licensing and your StandBy server, should it need to be used for any production activity during your disaster recovery:
"I am not the licensing police, and I am not Microsoft – check with your licensing representative to clarify your exact situation. Generally, you can have one warm standby server. However, the second someone starts using it for reporting, testing, or anything else, you need to license it like any other server."-Brent Ozar
**"If the database is in Standby mode, users can query it – except when a log backup is being restored. You need to decide if a restore job will disconnect users, or if the restore is delayed until after the users are disconnected." -Brent Ozar
Blockchain, apart from all the hoopla heralding it as a "cryptic" means of facilitating monetary transactions, is essentially just a distributed digital ledger (multiple sources of the exact same truth) and distributed digital notaries (transaction verifiers) who, unlike human money handlers and human notaries- do not lie.
Transactions can be scheduled via any desired logic (ie. loan repayment terms, payroll distribution, annuity payouts, securities purchase/sale/options, etc.) and encryption lies at the foundation of the technology- ensuring data integrity and information security.
Blockchain is a type of DLT design. DLT is well-illustrated below:
Much like Git commits, each blockchain transaction is forever tied to an unmodifiable unique SHA-256 hash sum value that ensures the immutability (un-changeability) of each transaction- in brief, if the transaction changes, the original SHA-256 hash sum (unique file signature) that has already been distributed to all nodes of the blockchain- will not match the modified transaction's SHA-256 hash sum, and everyone connected to the blockchain will be able to see that someone is trying to commit a fraudulent transaction modification. So changes to already-posted transactions within a blockchain digital ledger (in theory at least) are virtually impossible.
Definition from Microsoft: SQL Temporal Tables, also known as "system-versioned tables" are a database feature that brings built-in support for providing information about data stored in the table at any point in time rather than only the data that is correct at the current moment in time. Temporal is a database feature that was introduced in ANSI SQL 2011.
What is it used for?
1). Auditing Data History- identifying who did what, when, and row-level restoration to the state of the temporal table data any point in time. (Time travel)
2). Monitor Data Deltas(ie. maintain company sales discounting policy by ensuring no product has had a price change that exceeds some company threshold (200% increase or decrease, etc.))
3). Slowly Changing Dimension management (eliminate the need for complicated ETL logic for tracking SCD- SQL Temporal Tables do this audit tracking automatically)
In Practice
Once upon a time, I worked on a project that had a "unique" (kind euphemism) legacy database schema design. This company had a custom "system" for tracking changes in data. There was no referential integrity so everything relied on application code not having any data access code bugs, which as we all know is not a particularly reliable setup.
Temporal Tables would have done the trick without all the complexity of having to manage a proprietary data versioning system that sometimes worked, oftentimes caused headaches and mass confusion over the root cause of production issues related to versioning of certain data entities.
Temporal Tables have the current or base table, as well as a history table that logs changes over time
Unless there is a specific reason that SQL Temporal Tables won't work for your scenario* you should take advantage of existing functionality like this so that you can focus on the unique functionality of your app and not waste precious time reinventing wheels.
Creating a temporal table is relatively straightforward. In SSMS (connected to an instance of SQL Server 2016 or later), select the option as seen below.
Menu option in SSMS
Here is the T-SQL for basic Temporal Table DDL:
USE [KpItSimpl]
GO
--Create system-versioned temporal table. It must have primary key and two datetime2 columns that are part of SYSTEM_TIME period definition
CREATE TABLE dbo.SimplTemporalTable
(
--Table PK and columns definition
ProductID int NOT NULL PRIMARY KEY CLUSTERED,
ProductDescription varchar(max) NULL,
ProductPrice decimal,
--Period columns and PERIOD FOR SYSTEM_TIME definition
ValidFrom datetime2 (2) GENERATED ALWAYS AS ROW START,
ValidTo datetime2 (2) GENERATED ALWAYS AS ROW END,
PERIOD FOR SYSTEM_TIME (ValidFrom, ValidTo)
)
WITH (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.SimplTemporalTableHistory));
GO
T-SQL DDL for creating a new Temporal Table
For a practical example, I inserted some data into this temporal table, and then committed some UPDATE statements on that data, changing the ProductPrice value of some of the product records. The query below demonstrates how we can look for records (we are likely most interested in the exact change time) that had a price change exceeding +/- 200%:
Example of a query utilizing the Temporal Table feature to see an excessive product price change
Note(!) one limitation that stands out right away- you cannot drop a temporal table like a standard SQL table. You must turn versioning off on the table, drop the table and drop the history table. So instead of selecting "Delete" from the Table menu options or executing "DROP TABLE", you will want to select "SCRIPT AS >> DROP To" option as seen below:
You must script the deletion/drop of a SQL temporal table
As you can see, SQL Temporal Tables can make managing data changes a lot easier. Certainly much easier than a proprietary change versioning system and much faster than restoring the entire database to inspect the state of data at a particular point in time.