To keep it short and sweet let's go with the definition:
"A small multiple (sometimes called trellis chart, lattice chart, grid chart, or panel chart) is a series of similar graphs or charts using the same scale and axes,allowing them to be easily compared. It uses multiple views to show different partitions of a dataset."
Read any serious visual communication guide and it will invariably highlight this powerful tool we have at our disposal when we have the data (we almost always have the data).
A pair of Small Multiples example quite pertinent to the current times followed by some other good ones:
This CNN.com graphic captures a running snapshot of the "new case/spread" curve trajectory of individual states
This clearly communicates how each state unemployment picture fared from 1976-2009
This SM visual shows population change over time by country (look at Mexico's growth since 1960)
This app's function/purpose is to use Google Maps API to get geographic data and render locations on maps with editable pins (much like... many apps these days- it is kind of becoming an expectation for any application/service involving a location street address).
In this way you can record or plan the state(s) of an event or location at some particular street address. Or just have a geographic representation of some important locations that you can then print and have a custom map for.
This is a proof-of-concept app illustrating what you can do with a little JavaScript, a web app and the Google Maps API
The code below takes locations records (containing the lat/long of the geographic coordinate) from a database and then initializes the Google Map with some options (I omitted many for brevity). The main interesting thing the code does below, is when it renders the pins (addMarker() function) it adds an event listener to delegate the task of popping up an ASP.NET Core-bound edit modal when a user clicks the pin.
On the Add and Update side as far as mapping Lat/Long from Street, City, State- that is all handled by the incredibly useful GoogleLocationService provided as a Nuget package for .NET Core apps.
Other than that it is just standard JavaScript- Google Maps API does virtually all of the geocoding and map visualization heavy lifting.
The crux of the utilization of the API code (callback and map rendering) is this:
<script>
function initMap() {
var map = new google.maps.Map(
document.getElementById('map'),
{
center: new google.maps.LatLng(@Model.CenterLat, @Model.CenterLong),
zoom: 8
}
);
var pins = @Html.Raw(Json.Serialize(@Model.Locations));
for (var i = 0; i < pins.length; i++) {
var myLatLng = {
lat: pins[i].lat,
lng: pins[i].long
};
addMarker(myLatLng, map, pins[i]);
}
}
function addMarkerAsync(location, map) {
new google.maps.Marker({
position: location,
title: 'Home Center',
});
marker.setMap(map);
}
function addMarker(location, map, pin) {
var marker = new google.maps.Marker({
position: location,
title: '...something dyanmic...',
});
var infowindow = new google.maps.InfoWindow({
content: ''
});
function AsyncDisplayString() {
$.ajax({
type: 'GET',
url: '/Home/GetLocationModalInfo',
dataType: "HTML",
contentType: 'application/json',
traditional: true,
data: pin,
success: function (result) {
debugger;
infowindow.setContent('<div style="background-color:#000000;">' + result + '</div>');
infowindow.open(map, marker);
},
error: function (arg) {
alert('Error');
}
});
}
google.maps.event.addListener(marker, 'click', function () {
AsyncDisplayString(map, marker)
});
marker.setMap(map);
}
</script>
And then this Controller Action that uses GoogleLocationService to get coordinates by address:
This is a proof-of-concept app illustrating what you can do with a little JavaScript, a web app and the Google Maps API
As you can see the Google Maps API provides a lot of opportunity for your application- don't underestimate the power of location-based data. With the tools at our disposal today the functionality of applications is being limited less by available algorithms/frameworks/tools- but rather, our imagination.
I strongly suggest you look into the ways you can integrate geographic/mapped data with Google Maps API; very powerful API
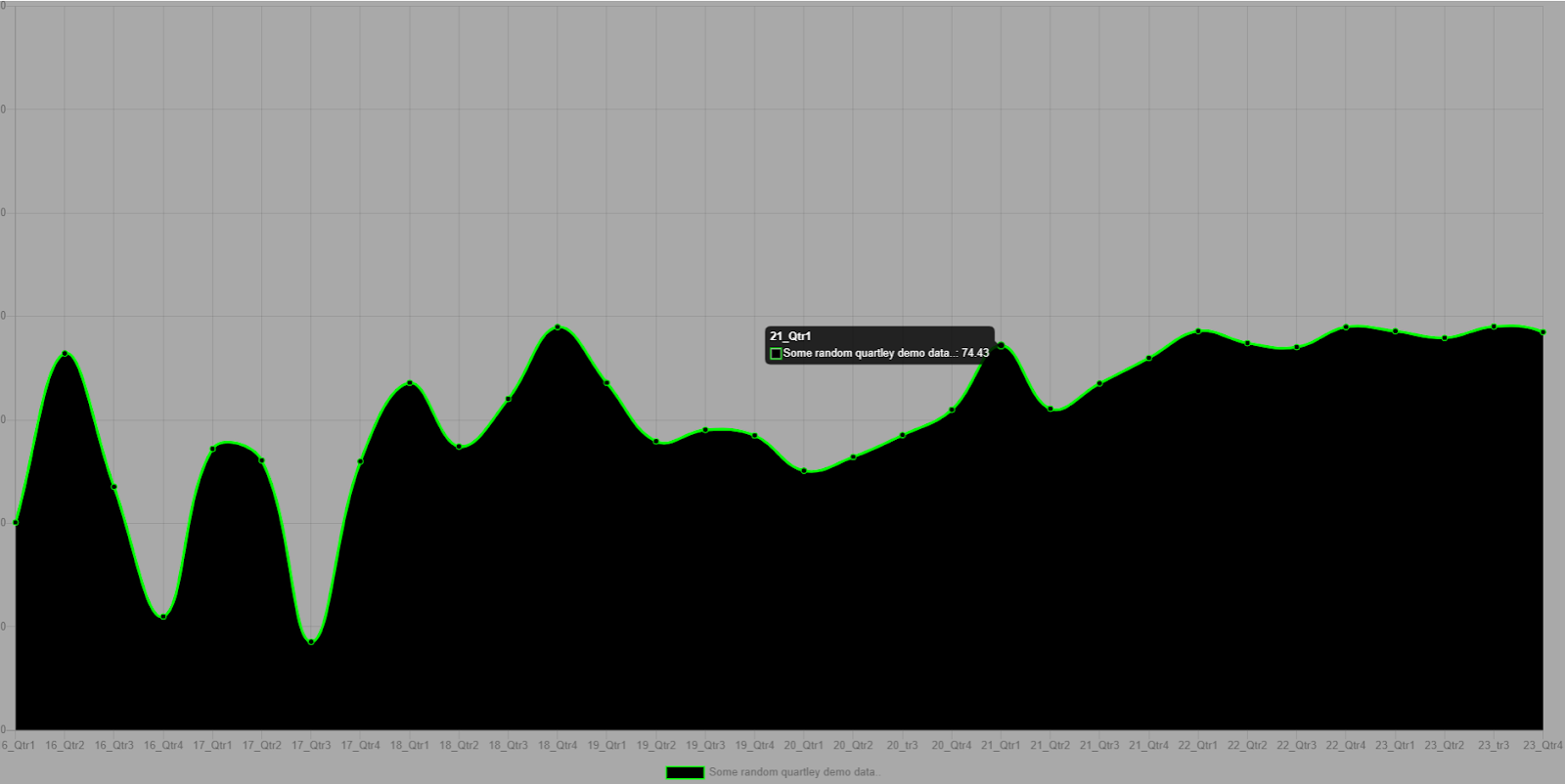
I came across ChartJS about 2 years ago while debugging code from another, similar data visualization technology inside an AngularJS app.
ChartJS is a flexible JavaScript data visualization framework which allows for some pretty powerful integrations and customizations
The concept is you have a "<canvas>" DOM element, which you transform into a ChartJS chart via some JavaScript initialization. After that your tasks are simply finding the data you want to render and deciding the options of exactly how you want the chart visual to appear.
You can do some really neat and dynamic stuff with ChartJS.
I have used a lot of charting frameworks, and it does not get more flexible or simple than this:
Here is a response from the SSSR REST API in action.. (you can access a lot more SSRS item properties and customize at will once you know the API)
The SSRS API v2 has far more functionality than v1, but they essentially work the same. You must be authenticated to the SSRS report server you are targeting (localhost in this case) to make web GET/POST requests to the API.
Once auth'd you can push and pull any useful SSRS data pretty easily to make SSRS do some pretty cool things it can't do out of the box..
This is the SSRS API as accessed through a web browser; simply give your .NET app an HttpClient and you can make use of all these responses; it's just JSON...
You can get a collection of SSRS catalog items as in the example above (folders, reports, KPIs) by just specifying the action name, or you can select an individual item by putting the item GUID in parenthesis in the API request URL:
You can access individual items in the API via GUID in parens after the API action name.
Common Useful SSRS API v2 Actions:
Reports
Datasets
Data Sources
Folders
Schedules
Subscriptions
Comments
KPIs
CatalogItems (everything)
Example of a .NET Standard library with an HttpService abstacting the SSRS API calls:
namespace ExtRS
{
public class SSRSHttpService
{
const string ssrsApiURI = "https://localhost/reports/api/v2.0";
HttpClient client = new HttpClient(new HttpClientHandler() { UseDefaultCredentials = true });
public async Task<GenericItem> GetReportAsync(Guid id)
{
client.BaseAddress = new Uri(ssrsApiURI + string.Format("/reports({0})", id));
var response = await client.GetAsync(client.BaseAddress);
var odata = response.Content.ReadAsStringAsync().Result;
return JsonConvert.DeserializeObject<GenericItem>(odata);
}
}
}
This is verbose to better break down the steps of what is happening on the ExtRS service end
A very basic class designed to demonstrate using SSRS API Response to create a .NET object:
using Newtonsoft.Json;
using System.Collections.Generic;
namespace ExtRS
{
public class GenericItem
{
[JsonProperty("@odata.context")]
public string ODataContext { get; set; }
[JsonProperty("Id")]
public string Id { get; set; }
[JsonProperty("Name")]
public string Name { get; set; }
[JsonProperty("Path")]
public string Path { get; set; }
}
}
The power of the SSRS API is limited primarily your imagination- lots of customization can be made
And finally, called from a Controller Action in an MVC app:
using System;
using System.Web.Mvc;
using System.Threading.Tasks;
using ExtRS;
namespace Daylite.Controllers
{
public class ReportsController : Controller
{
public SSRSHttpService service = new SSRSHttpService();
public async Task<ViewResult> GetReportsAsync()
{
return View("Index", await service.GetReportsAsync());
}
public async Task<ViewResult> GetFoldersAsync()
{
APIGenericItemsResponse result = await service.GetFoldersAsync();
return View("Index", result);
}
public async Task<ViewResult> GetReportAsync(Guid id)
{
GenericItem result = await service.GetReportAsync(id);
return View("Index", result);
}
}
}
TL; DR; - build the app; not your imagined future state of the app
Implementing what you know you will absolutely need before all else is the best course of action for development
This is a great brief guide on how it happens and how to prevent or at least diminish the phenomena that is borne out of a desire to do things exact and right- but ignores that fact that some things never are evaluated and time is.... finite. (in (virtually) every project, we only have so much time to get the bells to ring and the whistles to whistle...
That interface to allow for a potential future Python SDK, putting a small proprietary API on Swagger with loads of documentation and test calls just "because" might not be a road you want to go down yet..
Creating a .NET Standard portable class library of the core functionality with a full suite of tests because you think it may be Nugetized in the future... is not something you should do until the app is already engineered and built well, out the door and humming along swimmingly!
Over-engineering is essentially development of designs and/or writing code that solves problems that do not currently exist.
BugZilla learned the hard way that "Future-Proofing" taking too literally can become over-engineering and waste lots of time for stuff never to be used/needed
Bugzillahas dealt with it and a former developer left a very concise and telling quote from their experience:
Some people think design means, “Write down exactly how you’re going to implement an entire project, from here until 2050.” That won’t work, brother. That design is too rigid–it doesn’t allow your requirements to change. And believe me, your requirements are going to change.
Planning is good. I should probably do more planning myself, when it comes to writing code.
But even if you don’t write out detailed plans, you’ll be fine as long as your changes are always small and easily extendable for that unknown future.
-Max
TAKEAWAY:
"Business requirements never converge. They always diverge."
"At the beginning, it’s best to stick to the KISS principle over DRY."
Favor less abstraction for things that are currently 100% exactly known
Long ago one of my software engineering colleagues at a large Milwaukee-based industrial company (thanks John Ignasiak!) taught me a way to use what is known as "soft coding" in relational SQL to use data abstraction tables in order to abstract data types until run-time and multi-purpose data types and relations whilst keeping all values in the same table.
Just never enough generalizations and assumptions to make in software development... lol
I am not a big fan of multi-purposing things. But sometimes it is the only way and in this case of a legacy system with an old reporting db, it was the only way for time we had available.
Use the tools for the task they were made for.
Use the data type (VARCHAR for instance) for the data it was made for, not for dynamic SQL and hard-coded but dynamically inferred data types. The latter usages are almost always symptomatic of a terrible, terrible database design or something that your design just cannot accommodate without major restructuring of relational hierarchy and dependencies.
That all being said, SQL soft-coding (and dynamic SQL) is awesome and has some really powerful use cases where it is the perfect approach for the task at hand.
Build the app by the requirements as they currently exist, not by your imagination of how the future may or may not affect the app.
Two principals that have helped many a developer over the years are the acronyms:
I agree with everything except Atwood's (huh? 😨- keep in mind this is 2006) conclusion that we should do one or the other: objects or relational data records. Develop apps as a series of SQL data access statements assigning values to arbitrary pieces of monolith application code.. or exclusively object-oriented with everything saved to blob storage... Or something awkward like that.
That, he says (in the 2006 article*), removes the O (object) - R (relational data) mapping problem entirely. It sure does; but how can we develop apps like that?
(fast-forward 6yrs, and.... Dapper to the rescue!)
Dapper is an awesome (IMO) alternative that allows developers to retain SOLID reuse and extensibility in their .NET data access code while still accessing complex relational data- and fast.
Dapper has the best of both worlds in terms of what you look for in a data access framework - speed and clean, easy SQL-to-typed object mapping facilitation
I highly recommend the brief peruse; it is a very interesting article. It essentially describes the pitfalls that ADO.NET, Hibernate and Entity SQL (EF for MSSQL) and so many of the other approaches to modeling relational data as .NET objects that have, if not failed completely- severely been lacking especially in terms of speed and control over the actual SQL that you instruct the SQL engine to execute.
Dapper aims to bridge the eternal gap between application and relational database code in a pretty elegant way for .NET development. So long as your database records (whether from a complex JOIN'd SP or wherever in your db)- can return data with types and field/alias names that match your "query-return-target-type" class' properties' names and data types, you are set for all the kinds of data access you like and are off and running without all the headaches normally associated with ORMs (magic config strings, mappings in separate files out of sync with class or db changes, etc.).
"there is no good solution to the object/relational mapping problem. There are solutions, sure, but they all involve serious, painful tradeoffs. And the worst part is that you can't usually see the consequences of these tradeoffs until much later in the development cycle." -Jeff Atwood on ORMs
I guess you could say that the SQL itself in the queries you tell Dapper to issue to MSSQL are "magic strings" insofar as VS doesn't compile them.. But if you don't use SSMS to parse and execute tests of your queries before using them in application code then you aren't really doing real data development- you are just shooting in the dark.
You should have unit tests for this very purpose. Unit tests of your Dapper calls will catch any db changes in the tests ("hey why did nobody tell me about this schema change in the Archives table?"); regardless- if your SQL field names don't match the class prop names of the object you are trying to "Dapperize"- you will find out at run-time. The exception messages are very "straight to the point of exactly what is off".
Dapper works the same in all versions of .NET; it is currently based on .NET Standard for that very reason, but you will need to bring in more dependency depending on what type of data source you are trying to access (SQL Server, MySQL, Oracle, DB2, Terradata, etc.).
Consider giving Dapper a try - it is very useful and illuminating, and it really shines in the very areas where EF falls short.
Dapper accessing 'UserReport' records from SQL db and returning the dynamic, typed object:
SqlConnection db = new SqlConnection(WebConfigurationManager.AppSettings["DefaultSQLConnection"]);
public List<UserReport> ReadAllSavedUserReports()
{
using (db)
{
return db.Query<Report>("SELECT * FROM CLARO.dbo.UserReport").ToList();
}
}
public UserReport FindSavedUserReport(int id)
{
using (db)
{
return db.Query<Report>("SELECT * FROM CLARO.dbo.UserReport WHERE Id = @Id", new { id }).SingleOrDefault();
}
}
Forgive the "SELECT *.... this is just a demonstration..
These methods can then easily be called in controller or other code like so:
public ViewResult Index()
{
string nowTime = DateTime.Now.ToShortDateString();
ReportDAL dal = new ReportDAL();
Demo model = BuildModel(BuildSQLStatement(nowTime, ReportDrafts.BaseballDemo), nowTime);
model.Reports = dal.ReadAllSavedUserReports();
return View(model);
}
Dapper is not a company trying to sell anything- it is just a really useful micro-ORM for those who prefer to work more hands-on with the SQL in data access code (and like to be able to more granularily control optimization for speedier queries).
Net Present Value (NPV) and Internal Rate of Rerturn (IRR) are quite similar financial expressions.
In fact the two share the same formula (same variables being measured), but use it to describe the present value of something from 2 different perspectives - (1) what is this project's expected future cashflow currently worth is today's dollars? vs. (2) how profitable (%-wise) will the return on project investment be based on (1)?
NPV = Net present value is today’s value of the expected future cash flows.
If NPV is positive, the project is estimated to be profitable
IRR = The expected rate of return from the proejct.
If the IRR of a project is higher than the WACC, the project is estimated to be profitable
The below simple spreadsheet area explains both concepts nicely. This project would generate a $3.7k profit (NPV) over 5yrs and have a significantly profitable 15.64% IRR, higher than the 8% WACC of the 20k invested.
The project's estimated cash inflows over 5 years would add value, on paper at least
A common modern convenience for apps is the ability to choose to authenticate and create an account based on credentials from an existing service that most people have (ie. Google, Twitter, LinkedIn, GitHub, etc.). in this post I will walk through the configuration of social authentication for Google and LinkedIn accounts.
Setting up social authentication in ASP.NET Core is a lot easier than you might think...
Before implementing this feature you will need to register for a Google and a LinkedIn developer account which will then give you access to the 2 values that make the magic of this built-in authentication possible: clientKey and clientSecret. Important(!): you will also want to register the Callback/Redirect URLs for each social authentication as shown below. This redirect URL below is for my project running on localhost:44396 obviously ("/signin-google" is the path you want to append to your app root for Google and "/signin-linkedin" for LinkedIn):
Once you have this setup, you will be able to wire them up in the Startup.cs ConfigureServices() method of an ASP.NET Core 3 MVC Web Application ie:
Create your ASP.NET Core 3 MVC Web Application project with Identity options as below
Install a couple Nuget packages for Google OAuth2 and Linked OAuth respectively
Call "Update-Database" from Nuget Package Manager Console
Modify Startup.cs
To implement this feature for your users you only need follow a couple steps when setting up the project (whether ASP.NET MVC or the newer ASP.NET Core MVC) to enable some builtin identify and authentication handling after which you can configure and customize to fit your app's particular custom authentication needs. Follow the images below for proper installation of the required 2 Nuget packages, the db command, etc.
First, make sure you create your ASP.NET Core MVC project with "Individual User Accounts" radio button selection and "Store user accounts in app" dropdown selection as follows:
Change Authentication to use Individual User Accounts- this sets up the required boilerplate template code
You will add this Nuget package for LinkedIn authentication
You will add this Nuget package for Google authentication
Next you will need to create the database objects (ASPNET app auth db and tables) via "Update-Database" Package Manager Console command
Finally, modify Startup.cs ConfigureServices() method as shown in the snippet above. Compile and give it a whirl.
And that is all there is to it. Strangely there is not a lot of documentation on exactly how to do this and what can cause it to not work; I spent over an hour debugging what turned out to be a not-so-obvious issue (in my case I was following instructions that erroneously suggested I inject unneeded services to the services.AddAuthentication() instantiation in the snippet of Startup.cs above).
If your keys and Callback URLs are correct you will be able to authenticate to Google and LinkedIn
Once you have registered your social account, you can then log in with it and you will see the following (notice "Hello!...." and "Logout")
If you are like me and do not want to keep to adding yet more and more credentials to LastPass, your users probably don't either. Implementing Social Authentication is a powerful tool that you can leverage with relative ease in ASP.NET Core 3 MVC Web apps.
If you have questions on implementing this or just need some help and general guidance, feel free to comment or drop me an email at colin@sonrai.io
Ultimately the two most important factors in growing money is the size (%) of growth (rate of return or ROR) and the rate of growth (or the number of times the investment earns interest on a certain balance total, that interest is added to the balance, and then the investor begins earning interest on this new, higher amount).
This is why investing in something that will return 5% in 1 year is much worse than an investment that will return 5% quarterly or 4 times a year as illustrated below:
Year 1: $1,000 (5%) == $1,050
-vs-
Quarter 1: $1,000 (5%) == $1,050.00
Quarter 2: $1,050 (5%) == 1,103
Quarter 3: 1,103 (5%) == $1,158
Quarter 4: $1,158 (5%) == $1,216
Would you rather receive $1,050 or $1,216 dollars after one year of making a $1,000 dollar loan? 🤔
The power of compound interest is even better illustrated in a chart of growth over a period of several years. The below chart illustrates earning 10% per year on a $1,000 investment for 10 consecutive years.
An example with more money and more growth shows more clearly the power of compound interest
The below graphic shows clearly how important it is to save early. In it, Amy is able to earn enough in 10 years of savings, to earn more over the course of 34 years by simply earning interest off the savings of her initial 10 years of investing. No more contributions- just by earning interest she will have earned more than someone else who skipped those first 10 years and began investing later in their career.
In fact, Ethan contributes $100/month for 24 years and is not able to earn as much as Amy did contributing $100/month for just 10 years because Amy began putting her money to work much earlier than Ethan.
So 10 years go by, Amy consistently saving, Ethan consistently not saving anything. Now(?) Ethan, deciding he needs to begin saving for retirement is starting out with a much lower investment ($1,239.72) than Amy is already at by year 10 ($17,485.70).
The true power of compound interest is in the utilization of time and the time value of money. Because money that is invested wisely (presumably) always has a positive return, if you forgo savings (as I and many of my generation have) earlier on in your career you are incurring a huge opportunity cost; that opportunity being 10 years of 10% growth on $100/month investment with compounding interest.
Ethan chose to decline that opportunity and paid for it by losing out on all of that investment + compounded interest he could have received in the first 10 years of his career ($17,485.70), like Amy did.
Simply put, if you plan to invest (in safe, sound investments), the earlier you start the better off you will be. You cannot buy back time and time is a key ingredient to the growth of money.
Amy (wisely) began investing much earlier than Ethan and because of it, she is able to invest far less and still earn more.
Have you ever wanted to convert an icon or photo to ASCII art? Fortunately there are lots of tools to do this out there. I looked around for one that works with Python 3+ and found a succinct, modular script that can output ASCII art from image files like the following:
The script is from Paul Bourke. There is very clear commenting on each step. Essentially, an image loaded from the "--file" argument is divided into a grid and each position of the grid is assigned certain ASCII character whose gray scale level most closely matches the average for that area of the image. I simply modified line 146 and 150 to demonstrate on console vs. the outfile.txt default.
Save the following as ascii.py:
#Python code to convert an image to ASCII image.
import sys, random, argparse
import numpy as np
import math
from PIL import Image
# gray scale level values from:
# http://paulbourke.net/dataformats/asciiart/
# 70 levels of gray
gscale1 = "$@B%8&WM#*oahkbdpqwmZO0QLCJUYXzcvunxrjft/\|()1{}[]?-_+~<>i!lI;:,\"^`'. "
# 10 levels of gray
gscale2 = '@%#*+=-:. '
def getAverageL(image):
# get image as numpy array
im = np.array(image)
# get shape
w,h = im.shape
# get average
return np.average(im.reshape(w*h))
def covertImageToAscii(fileName, cols, scale, moreLevels):
# declare globals
global gscale1, gscale2
# open image and convert to grayscale
image = Image.open(fileName).convert('L')
# store dimensions
W, H = image.size[0], image.size[1]
print("input image dims: %d x %d" % (W, H))
# compute width of tile
w = W/cols
# compute tile height based on aspect ratio and scale
h = w/scale
# compute number of rows
rows = int(H/h)
print("cols: %d, rows: %d" % (cols, rows))
print("tile dims: %d x %d" % (w, h))
# check if image size is too small
if cols > W or rows > H:
print("Image too small for specified cols!")
exit(0)
# ascii image is a list of character strings
aimg = []
# generate list of dimensions
for j in range(rows):
y1 = int(j*h)
y2 = int((j+1)*h)
# correct last tile
if j == rows-1:
y2 = H
# append an empty string
aimg.append("")
for i in range(cols):
# crop image to tile
x1 = int(i*w)
x2 = int((i+1)*w)
# correct last tile
if i == cols-1:
x2 = W
# crop image to extract tile
img = image.crop((x1, y1, x2, y2))
# get average luminance
avg = int(getAverageL(img))
# look up ascii char
if moreLevels:
gsval = gscale1[int((avg*69)/255)]
else:
gsval = gscale2[int((avg*9)/255)]
# append ascii char to string
aimg[j] += gsval
# return txt image
return aimg
# main() function
def main():
# create parser
descStr = "This program converts an image into ASCII art."
parser = argparse.ArgumentParser(description=descStr)
# add expected arguments
parser.add_argument('--file', dest='imgFile', required=True)
parser.add_argument('--scale', dest='scale', required=False)
parser.add_argument('--out', dest='outFile', required=False)
parser.add_argument('--cols', dest='cols', required=False)
parser.add_argument('--morelevels',dest='moreLevels',action='store_true')
# parse args
args = parser.parse_args()
imgFile = args.imgFile
# set output file
outFile = 'out.txt'
if args.outFile:
outFile = args.outFile
# set scale default as 0.43 which suits
# a Courier font
scale = 0.43
if args.scale:
scale = float(args.scale)
# set cols
cols = 80
if args.cols:
cols = int(args.cols)
print('generating ASCII art...')
# convert image to ascii txt
aimg = covertImageToAscii(imgFile, cols, scale, args.moreLevels)
# open file
f = open(outFile, 'w')
# write to <console or> file ..f.write(row + '\n')
for row in aimg:
print(row + '\n')
# cleanup
f.close()
print("ASCII art written to console...") # %s" % outFile)
# call main
if __name__ == '__main__':
main()
Using Windows CMD, navigate to the directory where your ascii.py script is located. Then execute the following: ascii.py --file C:\somedir\logo.jpg --cols 150
DevOps is an emerging IT role but also a culture; and changing culture does not happen overnight
Elevate empowerment and give courage to people to "raise hand" and volunteer to fix things. Even if they are wrong- interest in areas outside one's primary role is good for the entire DevOps culture.
Shared accountability - no blame game between developers, PMs, testers, QA, etc.
Do not want to have to be dependent on "lone genius" or "firefighter"- need to share and transfer knowledge.
Offer time to learn.Encourage hacking for new features and for hardening security and find bugs.
Embrace failures in retrospectives to prevent repeated mistakeson future work.
Provide the right incentives to motivatve the values you want to reward: reward delivery of quality vs. fire fighting.
Understand "value streams"(esp. value stream bottleneck and how can we optimize all constraints) to know where to spend time accordingly.
Focus on CONSTRAINTS.
Avoid Configuration Drift- Config changes should cascade to all environments (QA, DEV, TEST, STAGE, PROD).
Automate the Path to Production.
Use pull-based systems so that people integrate each others changes and learn how everything works in unison/concert.
People should not fear for their jobs- Systems Admin becomes more important not less so, in DevOps
DevOps is how you work not just what you buy or what tech you are using.
Total adoption happens in stages/iterations.
Traditional Project and Documentation mindset is outmoded, outdated, and disconnected from a living IT mission.
Lack of DevOps leads to waste and waiting (waiting for ppl with the right skills to work on things vs. having team that can easily shift contexts or frameworks/languages).
SHARE KNOWLEDGE AND EMPOWER COLLEAGUES TO DO MULTIPLE TASKSAND UNDERSTAND SOME OR ALL ASPECTS OF MULTIPLE RESPONSIBILITIES OF THE SOFTWARE PROCESS CHAIN.
Do you need a jet engine to get your results from point A to B or will a modest GM sedan suffice?
I'll take the above bad analogy further and posit that while sedans and cars on the ground require stringent rules and have to navigate much more rigid structures, a jet engine simply powers the jet ahead through constraint-less skies- it's purpose is to power something big- not to be concerned with other machinery of the craft (ie. RDBMS features eschewed by NoSQL solutions).
Do you need massive global data sync scale so that millions can connect and make changes and the results all (appear) real-time? If not, NoSQL is not always the right choice and neglecting to have any kind of schema for stored application data structures can present its own host of challenges in the future if (when) those structures change. But alas, you can use NoSQL for some things (Redis, image/BLOB storage) and an RDBMS for others (more structured records and things you want to restore to a point in time in the event of a server failure).
Relational databases tend to be scaled up; NoSQL solutions are scaled out
The SQL vs NoSQL (structured and transactional vs. semi-structured and "eventually consistent") debate is not a matter of one or the other and that's that. These are complementary technologies and should both be used- wherever you find app requirements that suggest one or the other makes the most sense.
When an application is meant to scale immensely and there is not a lot of data integrity, consistency, transaction or complex data structuring and transformation needs- NoSQL is your best bet and will far outscale even the most robust RDBMS server farm- at least at a much lower cost (at the cost of sacrificing features of an RDBMS which may not be needed).
I have personally worked on several projects that utilize relational and unstructured approaches to reading and persisting application data. If you have ever used an application's config file to change a setting in JSON or XML or a simple line entry- you are seeing a small and very basic NoSQL example of storing app data.
Hadoop and other distributed NoSQL db servers are built for scalability
Using NoSQL in software development can make data structures and objects- passed to and fro from APIs and within the application itself- much more flexible to work with. 1-line to serialize an object to JSON chunk, save it to BLOB storage and forget about it.
When dealing with relational data, you really have to understand the data to write good data access code and the underlying SQL that supports well-defined structuring of complex objects.
Well-defined structuring of the persistence of complex application objects avoids data duplication/corruption, prevents breaking reference constraints and losing any sense of hierarchical data relationships and more generally lets you know very quickly when you have a problem within your data storage structures and the objects that initialize themselves from that data.
NoSQL ditches virtually all relational database data normalization rules in favor of a loosely schema'd unstructured (document, BLOB, KeyStore, etc.) data store that relies solely on keys, values and filtering unstructured metadata to get the same SELECT ... WHERE functionality found in RDBMS. Its iterations usually bear a resemblance to Java and as loosely follows here are common SQL statements and their Java or Java-derived equivalent:
"Apache Hadoop is an open source platform built on two technologies: Linux operating system and Java programming language."
For many application data requirements however, relational data can be overkill and totally unnecessary (ie. Redis to store key/vals vs. designing some elaborate key/val store in a SQL Server table).
Implementing something like Splunk or Kibana to continously index app logs and configuration files can help you dip toes into the Lake of Dark Data
The best distributed NoSQL solutions like Hadoop really shine in their inherit ability to dynamically scale to as many server machines as the operators can make ready to serve as "Hadoop processor nodes on standby".
SQL Server scaling is based more on server augmenting or "scaling up" (adding RAM, faster SSDs, RAID Arrays, etc.) rather than distributing workloads across dynamic nodes. SQL Server AlwaysOn Availability and its Mirroring and Replication feature are for recoverability and data sharing- not dynamic scaling to handle bigger and bigger workloads.
SQL has been around forever. The fundamental concept behind NoSQL (semi-structured or loosely structured data) has been around since long before SQL relational database technology. Both (along with NoSQL-related graph database paradigm) will continue to serve as viable data storage solution alternatives for many more years into the 21st century.
Relational systems like SQL Server, MySQL and Oracle usually handle structured side; NoSQL vendors are after the other 90%
In fact, SQL Server 2019's Polybase extension supports Hadoop Clusters, MongoDB and Terradata T-SQL query integration. A new feature called SQL Server Big Data Clusters helps make distributed NoSQL nodes manageable within SSMS environment.
Mongo, Hadoop and other NoSQL database servers have SQL server integration to support relational data sources.
SQL Server 2019 Polybase integrates Hadoop, MongoDB and many other sources with relational data and T-SQL queries
CAP Theorem: a distributed data system like most all NoSQL solutions can only achieve 2 of the 3 features: "Consistency", "Availability" and "Partition Tolerance"
ACID vs BASE: The relational axiom of "Atomic, Consistent, Isolated, Durable" contrasted against NoSQL's vague promise of "Basically Availability, Soft State, Eventual Consistency" (dirty reads common)
This ol' tried-and-true database server software ain't going away in the foreseeable future
Hundreds of millions of corporate, mid and small business applications are running along just fine in 2019 using various RDBMS platforms (SQL Server, Oracle, DB2, PostgreSQL, MySQL, etc.) for at least one of their data stores.
Many more millions of applications have been using one riff or another of NoSQL (semi-structured data) before, during and after the mythical "Relational Movement" as described by software veteran Robin Bloor:
"The Relational Model of Data Never Dominated Anyway. Estimates vary, but it is generally agreed that somewhere between 70% and 95% of the world’s data is stored only in poorly structured or unstructured formats such as: word processing documents, spreadsheets, HTML files and e-mail. The truth is that Relational database never did really dominate. It was rejected out of hand, year after year, as an effective store for many types of data."-Robin Bloor on insideanalysis.com
Google search trends over the last 5yrs certainly suggest relational SQL is not going anywhere anytime soon...
Considerations when evaluating whether to use NoSQL:
NoSQL is a precise tool for precise data needs; if relational SQL is too much for your group, NoSQL will likely be too steep a learning curve
Data Integrity- when billions of NoSQL records are affected by a small change in schema that is not able to propagate correctly or runs into constraint issues or hierachy and relations are impossible to infer... maybe relational SQL would be a better approach
NoSQL touts loose schema structure is a benefit but this simply means schema and data structure enforcement has been shifted from the database layer to the application layer. Data cannot "self-manage".
Some apps are prime candidates for NoSQL's document-centric and resource-centric distributed storage architecture
Also, there is this to consider:
(re: the longevity and simple-yet-powerful abstractions of SQL)
If NoSQL solutions are eventually able to achieve the same transactional consistency and complex schema structures that some applications require and then ultimately subsume RDBMS completely- it'll still require a lot of SQL gurus to convert and integrate all the legacy relational database apps for a long, long time to come...
Bring on MongoDB, CouchDB, Dynamo, MapReduce, HBase, BigTable, Cassandra.
As data professionals we will have an increasingly complex array of tools to understand; what we do with them will drive the future